
Det er en ting vi bare må innse: til tross for at datavitenskap ble kåret til den mest sexy jobben i det 21. århundre, så er det mange som blir nervøse når statistikk blir nevnt. Grunnen til at dette emnet virker så fremmed for mange, er statistikkens tette forhold til matematikk.
Denne artikkelen vil introdusere deg til emnet og hjelpe deg å komme i gang, så enten du sliter med å lære statistisk analyse, trenger litt repetisjon for å bestå statistikkeksamen, eller bare er nysgjerrig på å lære mer om det, så er det bare å lese videre.
Kjernen i statistikk er de samme fem essensielle begrepene som danner grunnlaget for dataanalyse. De fire første begrepene kan omtales uten å måtte gi veldig detaljerte beskrivelser:
-
Gjennomsnitt: gjennomsnittsverdien, den finner man ved å summere alle tallene i utvalget og deler summen på antall tall.
-
Median: midtpunktet i utvalget, som man finner ved å sette utvalget i stigende rekkefølge og tar verdien som står i midten.
-
Variasjon: variasjonsbredden i et datamateriale, defineres som den største og den minste verdien i datamaterialet.
-
Standardavvik: også et mål for spredningen til et datamateriale, regnes ut ved å ta kvadratroten av variansen.

I likhet med vitner i en detektivroman forteller disse fire begrepene deg historien om et bestemt datamateriale, for de er beskrivende statistikk. Hvis du for eksempel ser på menneskene som sitter rundt deg i en restaurant kan det være veldig vanskelig å skape en fortelling om dem, for det eneste du vet noe om er utseendet deres.
Det blir umiddelbart enklere hvis du derimot får informasjon om alder, månedlig inntekt, utdanningsnivå, kjønn og musikksmak. De to første begrepene, gjennomsnitt og median, er begge verktøy som forteller deg om mesteparten av materialet ditt er mennesker i tjueårene midt i studietiden sin eller velstående, eldre mennesker som investerer i hedgefond.
Forskjellen på de statistiske analysene avhenger av fordelingen av variabelen du måler i det aktuelle datamaterialet. I dette eksempelet avhenger det på variasjonen i mengden. Jo mer likt publikum er, jo mer nøyaktig vil gjennomsnittet være i formidlingen av historien din. Jo mer variasjon mellom folket er, jo mer nøyaktig blir bildet du tegner ved å ta gjennomsnittet.
Varians og standardavvik er begge målinger for variabilitet og forteller deg hvor forskjellig hver observasjon i datamaterialet ditt er fra gjennomsnittet i forhold til en bestemt variabel.
Hvis du ønsker å undersøke hvilken rolle alder spiller i datamaterialet ditt, må du starte med å beregne gjennomsnittsalderen og deretter variasjonsbredden i datamaterialet. Standardavviket forteller deg derimot hvordan datamaterialet ditt er gruppert rundt gjennomsnittet basert på en normalfordeling.
Standardavvik sier, akkurat som varians, noe om spredningen av datamaterialet ditt. Standardavvik beregnes av å ta kvadratroten av variansen. Forskjellen ligger i at standardavviket er det beskrivende tiltaket som er enklest å beregne, for det er i de samme enhetene som det opprinnelige datamaterialet, men variansen er ikke det. For å forstå hvorfor analyse av store mengder data er så viktig i dag, kan du lese denne artikkelen om hvorfor analyse av stordata er viktig.










Hva er sannsynlighet?
Nå som du vet de fire grunnleggende begrepene, er det på tide å lære den femte og viktigste byggesteinen i statistikk. Det er sannsynlighetsteori, som brukes for å forstå den viktigste grafen du vil se når du studerer statistikk på universitetet:
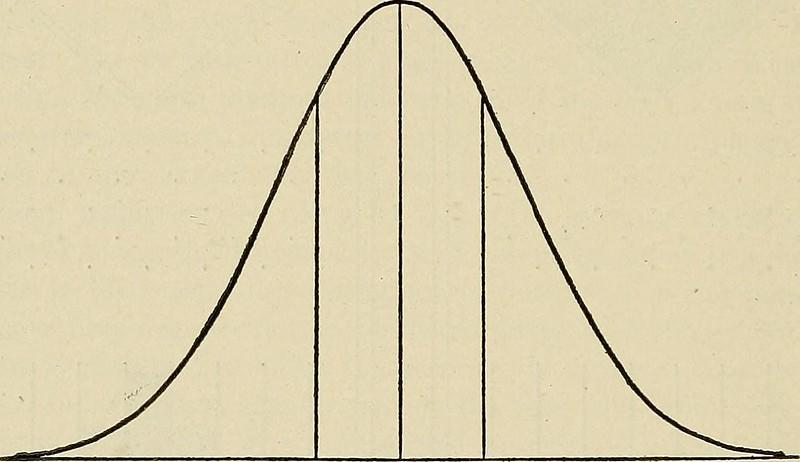
Denne grafen representerer normalfordeling, der datamengdene er ordnet symmetrisk rundt gjennomsnittet. Sannsynlighet brukes, med andre ord, for å forstå sentralgrensesetningen.
Sentralgrenseteoremet sier at summen av en uendelig mengde av suksessive variabler, som man henter fra populasjonen, vil gå mot en normalfordeling.
Det betyr at gjennomsnitt og standardavvik vil normaliseres i løpet av analysene, uavhengig av hvordan populasjonsfordelingen ser ut, og de vil se ut som grafen ovenfor. Sannsynlighetsforståelse gir en ikke bare språket man trenger for å snakke om normalfordeling, men det er også selve verktøyet til å kunne arbeide med det. For å dykke dypere inn i hvordan denne forståelsen brukes i ulike fagfelt, kan du lese en artikkel om forskjellene mellom datavitenskap og dataanalyse.
Hvordan velge en hypotesetest
Når du har lært deg det grunnleggende begrepene innen statistikk og det grunnleggende innen datavitenskap, kan det være vanskelig å takle neste steg. Det vil si å bestemme hvilken test som passer for ditt spesifikke datamateriale. Det finnes et bredt utvalg av statistiske tester og tilnærminger man kan bruke, og disse kan vi kategorisere i fire hovedgrupper:
-
Tilknytning
-
Sammenligning
-
Prediksjon
-
Ikke-parametrisk, det vil si data som ikke følger en normalfordeling
Det er viktig å skille mellom datamengdene basert på variablene man skal analysere, slik at man vet hvilken test man skal bruke. Variabler skal være enten skalavariabler eller kategoriske variabler.
Skalavariabler er kvantitative og deles i to kategorier;
-
Kontinuerlig: kan ha hvilken som helst verdi, for eksempel høyde
-
Diskret: heltall, for eksempel antall barn
Kategoriske variabler er kvalitative, og også disse deles i to kategorier:
-
Ordinal: har en åpenbar rekkefølge, for eksempel lykkeindeksen der man vurderer hvor lykkelig man er på en skala fra 1 til 10
-
Nominal: har ingen meningsfull rekkefølge, for eksempel kjønn
Når skal man bruke tilknytningstester?
Med disse testene ser man på forholdet mellom to variabler. Det er det nærmeste man kommer det å se på årsakssammenhengen mellom to variabler, for eksempel sivilstand og utdanningsnivå. Alle disse testene tester styrken av sammenhengen mellom to variabler:
| Test | Variabler | Eksempel |
|---|---|---|
| Pearson-korrelasjon | To kontinuerlige variabler | Har skostørrelse en sammenheng med høyde? |
| Spearman-korrelasjon | To ordinale variabler | Hvor sterk er sammenhengen mellom lykke og økonomisk status? |
| Kji-kvadrattest | To kategoriske variabler | Har kjønn og favorittfarge noen sammenheng? |
Tester for sammenligning av gjennomsnitt
Sammenligningstester omhandler å se på forskjellene mellom forskjellige variabler ved å se på forskjellen mellom gjennomsnittet til variablene, for eksempel forskjellige skolers eksamensresultater.
| Test | Variabler | Eksempel |
|---|---|---|
| Paret T-Test | To relaterte variabler | Forskjellen mellom vekt før og etter inntak av nytt tilskudd |
| Uavhengig T-test | To uavhengige variabler | Forskjellen i forbruk på bensin mellom innbyggerne i Los Angeles og innbyggerne i New York |
| Enveis variansanalyse (ANOVA) | En uavhengig variabel med forskjellige nivåer og en kontinuerlig variabel | Sammenligning av gjennomsnittsresultatene fra tre forskjellige utdanningsnivåer |
| Toveis variansanalyse (ANOVA) | To eller flere uavhengige variabler med forskjellige nivåer og en kontinuerlig variabel | Sammenligning av gjennomsnittsresultatene fra begge tre utdanningsnivåer og de tolv forskjellige stjernetegnene |
Prediksjonstester ved bruk av lineær regresjon
Prediksjonstester brukes til å finne ut om en endring i en eller flere variabler fører til endring i en annen, for eksempel om det er forskjeller i kjønn, kosthold og inntekt har noen innvirkning på et individs høyde.
| Test | Variabler | Eksempel |
|---|---|---|
| Enkel lineær regresjon | En skalavariabel (avhengig) med en eller to skalavariabler (prediktorer) | Du ønsker å finne ut om alder og høyde har en forutsetning for vekt |
| Multippel lineær regresjon | En skalavariabel (avhengig) med to eller flere skalavariabler (prediktorer) | Du ønsker å finne ut om alder, høyde og inntekt har en forutsetning for vekt |
Tester for ikke-parametriske data
Tester for ikke-paramatriske data skal brukes når dataene ikke oppfyller forutsetningene som ligger til grunn for de andre testene, for eksempel hvis fordelingen i datamengdene er skjev, og ikke følger en normalfordeling.
| Test | Variabler | Eksempel |
|---|---|---|
| Mann-Whitney U-test | To uavhengige variabler | To tilfeldige, forskjellige grupper av en befolking tester to forskjellige medikamenter, for å undersøke hvilke medikament gir den beste lettelsen |
| Wilcoxon-signert rangeringstest | To relaterte variabler | Hvilke medikament av to forskjellige medikamenter har best effekt på samme pasientgruppe? |
| Friedman-test | Tre metriske eller ordinale variabler (må enten være metriske eller ordinære) | Tre forskjellige annonsevurderinger gitt av enkeltpersoner i samme befolkning |
Hvordan utføre hypotesetester
Det er flere forutsetninger når du benytter statistiske tester, og for at resultatet skal være prediktiv og nøyaktig må datamengdene oppfylle disse forutsetningene. Det er forskjellige forutsetninger for forskjellige tester, så det er viktig å sjekke dem før du begynner å modellere datamengdene.
De vanligste programmene som brukes til statistisk analyse er:
-
Excel
-
Stats
-
SAS
-
SPSS
-
Python
-
R
Hvis du bruker tester for parametriske data, er det fire forutsetninger datamengdene må oppfylle. Forutsetningene er forskjellige for hver test, og det er noe man bør undersøke på forhånd. Listen overfor viser noen av de vanligste programmeringsspråkene, men det finnes dog mange flere.
| Antagelse | Beskrivelse |
|---|---|
| Normalitet | Datamaterialet i settet er normale, noe som betyr at det følger en normalfordeling |
| Selvstendighet | Datamengdene som gruppene består av, er uavhengige av hverandre |
| Homogenitet av varians | Hvis det er flere grupper i datamaterialet som er relatert til de uavhengige variablene, så har de samme varians |
Hvis du leter etter litt ekstrahjelp til introduksjonsemnene, er det mange nettbaserte ressurser du kan bruke for å forbedre ferdighetene dine. Veiledningsnettsteder som Superprof kan hjelpe deg med å komme i gang med prosessen med å finne noen som kan gi deg privatundervisning i statistikk. For en grundig oversikt over hva du kan forvente når du studerer statistikk, og hvordan du kan bygge et solid grunnlag, kan du lese denne artikkelen om å studere datavitenskap.
Oppsummer med AI:
Likte du artikkelen? Vurder den!



